
Cuando hablamos de SEO técnico, uno de los conceptos clave para tener el control de lo que Google indexa (o no) en tu sitio web es la etiqueta meta robots noindex. Si no quieres que ciertas páginas aparezcan en los resultados de búsqueda, esta etiqueta es la herramienta adecuada.
En este artículo te explicamos qué es la meta etiqueta noindex, para qué sirve, cómo implementarlo, errores comunes a evitar y otros aspectos clave para dominar su uso y proteger tu estrategia SEO.

¿Qué es la etiqueta meta robots noindex?
La etiqueta meta robots noindex es una instrucción HTML que le dice a los motores de búsqueda, como Google, que no deben indexar una determinada página. Es decir, les estás indicando que esa página no debe aparecer en los resultados de búsqueda.
Diferencias entre index y noindex
index: le dice a Google que puede indexar la página y mostrarla en los resultados.noindex: le indica que no debe hacerlo.
¿Qué significa “meta no index” en SEO?
Significa literalmente evitar que Google u otros buscadores incluyan esa página en su índice. Esto no impide el rastreo, pero sí bloquea su aparición en las SERPs.
¿Para qué sirve la etiqueta noindex en HTML?
La etiqueta noindex cumple una función esencial dentro del SEO técnico: ayuda a mantener el índice de Google enfocado únicamente en el contenido que aporta valor. En otras palabras, permite decirle a los motores de búsqueda qué páginas no deben incluirse en sus resultados.
Además de mejorar la calidad general del índice de tu web, el uso adecuado de noindex optimiza el presupuesto de rastreo (crawl budget), evita el contenido duplicado y protege páginas que no deberían ser visibles públicamente (como paneles privados, formularios, contenido en pruebas, etc.).
En sitios grandes, con miles o cientos de miles de URLs, noindex se vuelve aún más importante: si Google rastrea e indexa páginas de baja calidad, estás desperdiciando recursos que podrían ir dirigidos a tus páginas más relevantes.
Puedes corroborar y ampliar más información en la documentación oficial de google sobre noindex
¿Cuándo deberías usar noindex?
1. Páginas de baja calidad o sin contenido relevante
Contenido escaso, duplicado, generado automáticamente o que no responde a ninguna intención de búsqueda clara. Ejemplos: páginas de error vacías, landing pages sin desarrollo o fichas de producto sin descripción.
2. Resultados de búsqueda interna del propio sitio
Estas URLs suelen ser infinitas, con parámetros dinámicos y sin contenido único. Indexarlas puede generar thin content (contenido pobre) y perjudicar el SEO general.
3. Páginas de agradecimiento, formularios o pasos intermedios de conversión
Estas páginas son funcionales, no informativas. Indexarlas puede generar confusión o incluso riesgo de que un usuario acceda directamente a una página que debería verse sólo tras completar una acción.
4. Páginas duplicadas o con contenido muy similar
Es común en sitios e-commerce o blogs con muchas taxonomías. Las páginas con filtros, etiquetas, archivos por fecha o autor suelen repetir gran parte del contenido. En lugar de dejar que compitan entre sí en Google, se les puede aplicar noindex para evitar canibalización.
5. Archivos, contenidos temporales o privados
Como PDFs internos, páginas de test A/B, versiones antiguas de campañas o contenidos para usuarios registrados. Si no están pensadas para tráfico orgánico, no deberían indexarse.
¿Y cuándo NO deberías usar la etiqueta noindex?
Aunque noindex es útil para filtrar contenido de poco valor, hay situaciones en las que aplicar esta etiqueta puede dañar tu posicionamiento:
❌ Si la página responde a una intención de búsqueda clara
Por ejemplo, si tienes una guía sobre «cómo elegir un seguro de coche», esa página tiene potencial SEO y debe ser indexada. Aun si no está perfecta, es preferible optimizarla que bloquearla.
❌ Si recibe enlaces internos o externos de calidad
Los enlaces son señales de relevancia para Google. Si apuntas tus esfuerzos (y los de otros sitios) hacia una página, pero luego la marcas como noindex, estás desperdiciando autoridad.
❌ Si ofrece valor informativo, comercial o de navegación
Categorías con productos, artículos de blog, páginas de servicios… deben formar parte de tu estrategia de posicionamiento. Revisa sus estadísticas, pero no las bloquees sin razón de peso.
Si el contenido está desactualizado o es débil, mejora su calidad en lugar de eliminarlo del índice.
¿Qué pasa si no la usas correctamente?
Un mal uso de noindex puede generar varios problemas:
- Indexación de páginas innecesarias: Google podría mostrar páginas que no aportan valor, lo que reduce la autoridad del dominio y afecta al posicionamiento de páginas clave.
- Contenidos duplicados: Indexar varias versiones de la misma información puede hacer que el buscador no sepa cuál priorizar o que directamente penalice el dominio por duplicidad.
- Desperdicio del crawl budget: Googlebot tiene un límite para rastrear tu sitio. Si pierde tiempo en páginas sin valor, puede dejar de rastrear las que sí lo tienen.
- Confusión en la arquitectura del sitio: Al indexar todo sin filtro, tu mapa web se vuelve caótico y desorganizado tanto para Google como para el usuario.
- Desindexación involuntaria de páginas clave: Si aplicas noindex sin revisión, podrías eliminar del índice páginas importantes por error (como una landing principal o una categoría clave).
Por eso, es fundamental realizar auditorías SEO periódicas y revisar bien qué contenido debe (y no debe) estar indexado.
Cómo implementar noindex en tu sitio web
Hay varias formas de aplicar la etiqueta noindex, y la elección dependerá del tipo de plataforma que uses (HTML, WordPress, Shopify, etc.) y del acceso que tengas al código o a herramientas SEO.
Añadir en el código HTML mediante meta robots noindex
La forma clásica de implementar noindex es añadiendo esta línea dentro del <head> de la página:
<meta name="robots" content="noindex">
Esto le indica a Google y otros motores que no deben indexar esa página.
Si también deseas que no sigan los enlaces que contiene esa página, puedes añadir:
<meta name="robots" content="noindex, nofollow">
Aquí vemos un ejemplo de aplicación noindex en código fuente:
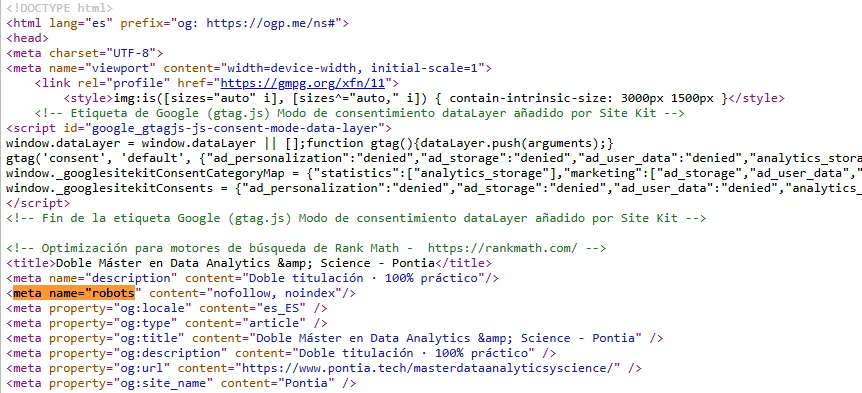
Esto impide que Google transmita autoridad hacia otras páginas a través de los enlaces internos o externos que incluya.
Otras formas de aplicar noindex
1. Mediante cabecera HTTP (X-Robots-Tag)
Especialmente útil si estás sirviendo archivos como PDFs o contenido que no tiene HTML editable. En este caso, puedes aplicar la directiva desde el servidor:
X-Robots-Tag: noindex
Aquí tenemos un ejemplo de etiqueta no-index aplicada en una cabecera http:
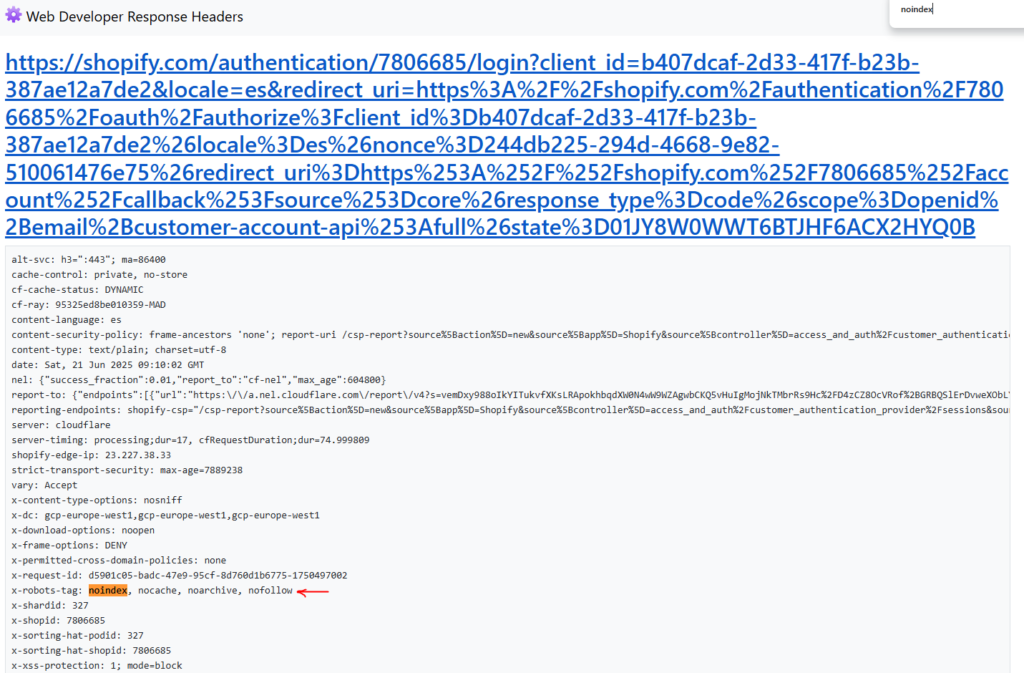
2. Con plugins SEO (WordPress y otros CMS)
Herramientas como Yoast SEO, Rank Math o All in One SEO facilitan esta tarea con una casilla de verificación en cada página, sin necesidad de tocar código.
3. Desde frameworks o CMS a medida
En sitios personalizados, puedes aplicar lógica condicional desde el backend para marcar automáticamente ciertas páginas como noindex (por ejemplo, productos sin stock, etiquetas vacías, etc.).
Meta robots noindex y su impacto en el SEO
El uso de la etiqueta meta robots noindex tiene un impacto directo en la visibilidad de tu sitio web en Google. Al bloquear la indexación de determinadas páginas, estás controlando qué contenido forma parte del índice de los motores de búsqueda y, por tanto, qué puede posicionarse.
Aplicar esta etiqueta no penaliza directamente tu SEO, pero su mal uso puede tener consecuencias negativas. Si tienes muchas páginas con poco valor indexadas, Google podría considerar que tu sitio tiene baja calidad general, lo que puede afectar a tu autoridad y a la capacidad de posicionar tus páginas importantes.
Indexación vs. rastreo: ¿afecta al posicionamiento?
Es importante entender la diferencia:
- Rastreo (Crawling): Google visita tu página.
- Indexación: Google decide incluir esa página en su índice (y por tanto, puede posicionarla).
Una página con noindex puede ser rastreada, pero no se añadirá al índice. Eso significa que no recibirá tráfico orgánico y no aportará directamente a tu posicionamiento.
Sin embargo, si Google rastrea cientos de páginas con noindex, desperdicias presupuesto de rastreo y podrías estar perdiendo oportunidades para tus páginas más valiosas.
Cómo comprobar si una página está con noindex
Podemos encontrar multitud de maneras para comprobar si una web tiene la etiqueta noindex implementada:
Google Search Console – Inspección de URL
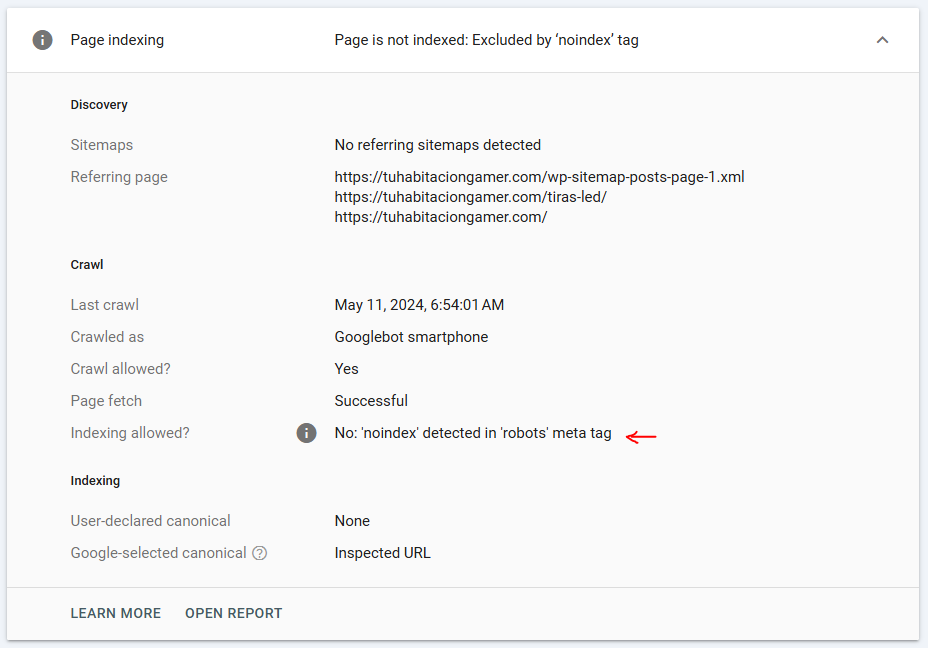
Introduce la URL en el inspector de url’s de search console y verifica el estado de indexación. Si aparece como “Excluida por ‘noindex’”, estás aplicando la etiqueta correctamente.
También podemos ver todas las url’s que no se indexan por tener aplicadas una etiqueta no-index. Para ello, ve a al informe de cobertura > páginas > donde encontrarás el siguiente apartado »Por qué las páginas no están indexadas».
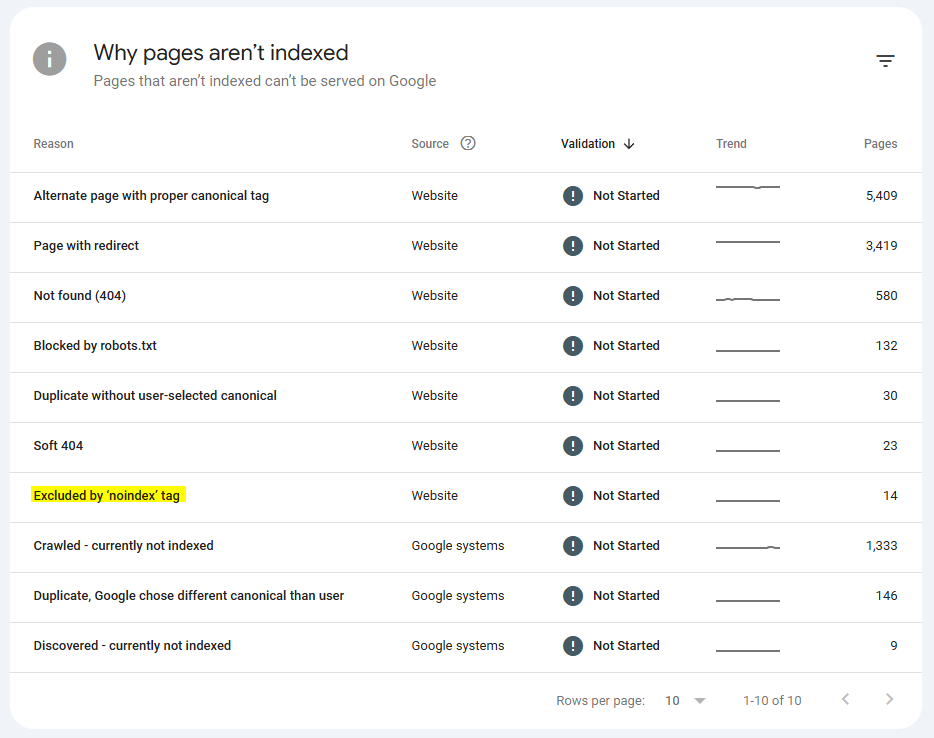
Haciendo click en esa sección, se mostrarán todas las páginas no indexadas con la etiqueta noindex.
Extensiones de navegador
Como Meta SEO inspector o SEO Meta in 1 Click, que te muestra en segundos las metaetiquetas activas de la página.
Al abrir estas extensiones, te mostrarán todo el head, dónde en el apartado »robots» aparecen las etiquetas etiquetas noindex o index, así como follow o no follow.
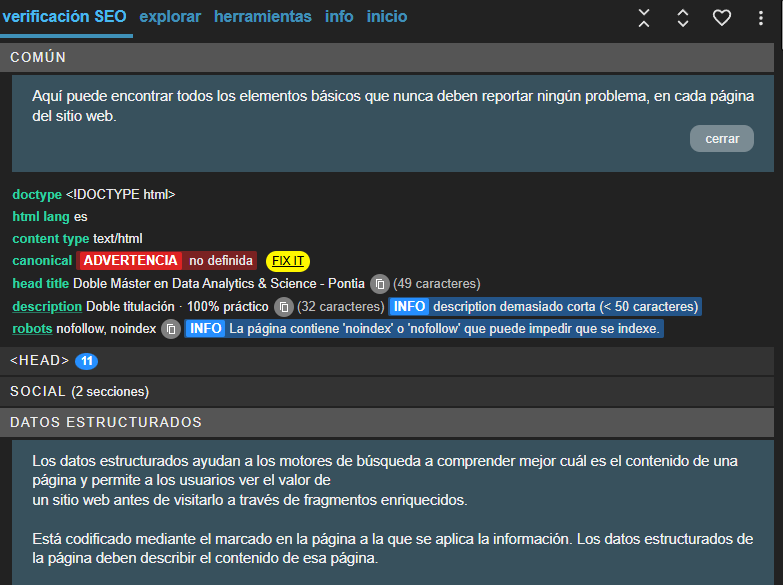
En este caso, vemos que esta url tiene la etiqueta noindex implementada.
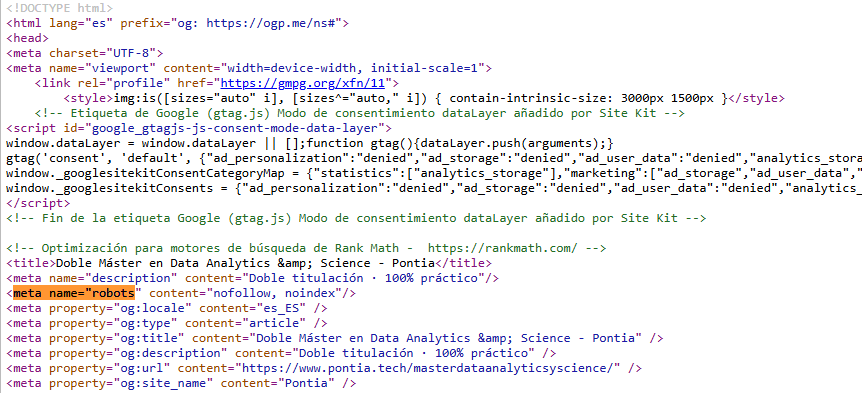
Verificación manual en el código fuente
Presiona Ctrl + U o haz clic derecho > Ver código fuente, y busca la línea: htmlCopiarEditar<meta name="robots" content="noindex">
Rastreo en screaming frog
Lanzando un rastreo en screaming frog, puedes detectar el conjunto de url’s de una web que tienen aplicadas la etiqueta noindex. Especialmente cuando quieres comprobar el estado de indexabilidad de un site de gran tamaño al completo.
Para verlo, hay que dirigirse al apartado directivas > noindex:

A la hora de realizar las comprobaciones, recuerda: Cuando no se específica etiqueta metarobots, es decir, no se ha implementado ni «index» ni »no index», las arañas lo interpretan como »index». Por lo que si al comprobar no vemos esta etiqueta, significa realmente que la página está index, como si tuviera aplicada la etiqueta »index».
Casos prácticos y ejemplos de uso de la etiqueta noindex
Implementar noindex de forma estratégica puede ayudarte a mantener la calidad del contenido indexado en tu sitio web. Aquí te muestro varios casos reales donde esta etiqueta es clave para mejorar tu posicionamiento general.
✅ Noindex en resultados de búsqueda interna
Las páginas que muestran resultados generados dinámicamente a partir del buscador interno (como tusitio.com/?s=producto) no aportan contenido único ni valioso por sí mismas. Dejar que se indexen puede generar:
- URLs infinitas con combinaciones de palabras clave sin sentido.
- Problemas de contenido duplicado si los resultados apuntan a productos ya indexados.
- Dilución del crawl budget, ya que Google gastará tiempo rastreando páginas de baja prioridad.
Aplicar la etiqueta <meta name="robots" content="noindex, follow"> en las plantillas de resultados de búsqueda, o configurarlo desde tu plugin SEO si usas CMS.
✅ Noindex en landing pages temporales o duplicadas
Durante campañas de publicidad, lanzamientos o promociones, se crean landing pages específicas, que a menudo son:
- Duplicados de una página principal ya optimizada.
- Versiones alternativas para A/B testing.
- Contenido que caduca en poco tiempo (por ejemplo, ofertas flash).
Estas páginas no deberían competir por las mismas palabras clave que las versiones permanentes. Si lo hacen, puedes sufrir canibalización SEO.
Usa noindex en las versiones temporales mientras haces pruebas. Si una landing demuestra buen rendimiento, cámbiala por la versión principal o elimínala adecuadamente.
✅ Noindex en páginas legales o de poco valor SEO
Documentos como:
- Términos y condiciones
- Políticas de privacidad
- Avisos legales
- Políticas de cookies
Son contenidos obligatorios, pero no responden a búsquedas transaccionales ni informativas relevantes para SEO. Además, suelen tener mucho texto duplicado (incluso con otros sitios).
Aplicar noindex para evitar que estas páginas consuman autoridad o interfieran con tu estrategia de posicionamiento.
Alternativas a la etiqueta noindex: ¿qué otras opciones tienes?
rel=canonical
Indica a Google cuál es la versión preferida entre varias páginas similares. No impide la indexación, pero consolida señales SEO y evita que se divida la autoridad entre duplicados.
Por ejemplo, tienes varias URLs con el mismo contenido por filtros (/camisetas?color=azul), pero quieres que solo se indexe /camisetas. Usa esta línea en las versiones duplicadas:
<link rel="canonical" href="https://tusitio.com/camisetas">
nofollow
Imide que Google siga los enlaces de una página, lo cual puede ser útil para:
- Comentarios con spam
- Enlaces externos que no quieres respaldar
- Enlaces de afiliados o patrocinados
A diferencia de noindex, la página puede seguir indexándose, pero no transfiere autoridad a través de sus enlaces.
robots.txt
Permite bloquear el acceso de los bots a determinadas rutas de tu sitio. No impide la indexación si la URL ya está en el índice de Google, pero evita que Google la rastree.
📛 Peligro común: Si bloqueas una URL en robots.txt, Google no podrá ver si en esa página hay una etiqueta noindex, y por tanto, podría seguir indexándola.
¿Cuándo combinar estas alternativas?
Dependiendo del objetivo, puedes usarlas juntas:
noindex, nofollow: para páginas que no quieres indexar ni transferir autoridad.noindex+canonical: ¡no recomendado! Son contradictorias. No lo hagas.nofollow+canonical: válido si quieres consolidar la autoridad, pero evitar seguir enlaces.
¿Qué hacer si Google sigue indexando una página con noindex?
✅ Revisa y valida la etiqueta
- Asegúrate de que esté en el
<head>correctamente. - No debe haber conflictos con otras etiquetas o encabezados HTTP.
- Comprueba que robots.txt no esté bloqueando la página antes de que Google pueda leer la etiqueta noindex.
✅ Usa Google Search Console
- Herramienta de Inspección de URL: te muestra si Google ha visto o está ignorando la directiva.
- Puedes solicitar eliminación temporal si necesitas que desaparezca cuanto antes del índice.
- También puedes pedir una nueva revisión si ya hiciste cambios.
Otras etiquetas meta robots que existen e influyen en SEO
| Etiqueta | Descripción | Uso recomendado |
|---|---|---|
nofollow | No seguir enlaces de la página | En comentarios, contenido generado por usuarios o enlaces de pago |
noarchive | No mostrar copia en caché | Para contenido sensible o que cambia con frecuencia |
nosnippet | No mostrar fragmentos de texto en los resultados | Para contenido premium o confidencial |
max-snippet | Limita la longitud del snippet en caracteres | Controla qué tanto texto se muestra |
max-image-preview | Limita la previsualización de imágenes | Útil para proteger propiedad visual o controlar clics desde imágenes |
¿Cómo evitar indexar contenido automáticamente?
🔧 Plugins y herramientas SEO
- Yoast SEO (WordPress): permite configurar qué tipos de contenido deben ser noindex (etiquetas, categorías vacías, autores…).
- Rank Math: incluso más granular, con opciones para taxonomías, páginas de archivo y más.
🧠 Reglas automatizadas en sitios grandes
En e-commerce o sitios de contenido dinámico, puedes crear reglas condicionales para noindexar:
- Productos sin stock o sin descripción
- Etiquetas con menos de X artículos
- URLs con determinados parámetros
Estas automatizaciones evitan errores humanos y mantienen tu sitio limpio y optimizado para Google.
Conclusión: Usa la etiqueta noindex con inteligencia
La etiqueta noindex es una herramienta fundamental dentro del SEO técnico. Bien utilizada, te ayuda a mantener tu sitio limpio, enfocado y libre de contenido que no aporta valor, evitando que Google pierda tiempo indexando páginas irrelevantes o duplicadas.
Sin embargo, su mal uso puede perjudicar gravemente tu posicionamiento, eliminando del índice páginas que sí deberían estar allí. Por eso, es clave que entiendas cuándo aplicarla, cómo combinarla con otras etiquetas como canonical o nofollow, y qué herramientas usar para comprobar su correcta implementación.
Piensa en el noindex como un filtro estratégico: no se trata de ocultar contenido sin más, sino de garantizar que lo que muestras a Google realmente merece estar posicionado.
🔎 ¿Tienes dudas sobre cómo aplicarlo en tu sitio? Revisa tus páginas más débiles, analiza su rendimiento y toma decisiones basadas en datos.
🛠️ Y recuerda: si usas un CMS como WordPress, aprovecha los plugins SEO para automatizar este proceso y evitar errores comunes.
¿Listo para mejorar tu estrategia de indexación? Empieza hoy a optimizar tu sitio con inteligencia.
Soy Daniel Caro García, consultor SEO con experiencia en ayudar a empresas de mediana y gran envergadura a mejorar su visibilidad online, trabajando tanto en agencia como en cliente final.
Me apasiona el SEO técnico y el análisis del comportamiento del usuario, lo que me permite desarrollar soluciones que no solo mejoran el posicionamiento, sino que también aportan valor real a las marcas con las que trabajo. A través de mi blog, comparto conocimientos, tendencias y estrategias prácticas que facilitan a otros profesionales y empresas mantenerse al día en un entorno digital en constante evolución.
Mi objetivo es ofrecer resultados medibles basados en datos y siempre dentro de las mejores prácticas de SEO, creando una presencia online sólida, ética y de confianza para mis clientes.