
¿Qué es el rastreo e indexación en SEO y por qué es tan importante?

Si estás empezando en el mundo del SEO o simplemente quieres entender mejor cómo funciona Google, probablemente te has topado con dos términos clave: rastreo e indexación. Son dos conceptos básicos pero fundamentales para que tu web pueda aparecer en los resultados de búsqueda.
En este artículo vamos a explicarte qué significan, cómo funcionan y qué puedes hacer para optimizarlos. Vamos paso a paso y sin complicaciones técnicas innecesarias.
¿Quieres aprender como hacer crecer tu negocio con SEO y Marketing digital?
Table of Contents
¿Qué es el rastreo en SEO y cómo funciona?
El rastreo (también conocido como crawling) es el proceso mediante el cual los motores de búsqueda, como Google, descubren el contenido que hay en tu sitio web. Lo hacen a través de unos bots o arañas que navegan por tus páginas, siguiendo enlaces y recopilando información.
Imagina a Googlebot como un lector muy rápido que va de página en página. Empieza por las URLs que ya conoce y luego sigue los enlaces internos para descubrir nuevas páginas. También puede encontrar nuevas páginas a través de tu sitemap o cuando otros sitios enlazan al tuyo.
Google accede a tu web como cualquier usuario, pero con ciertas reglas. Puede verse bloqueado por archivos como el robots.txt, por errores en el servidor o incluso por tener la web mal estructurada. Si Google no puede rastrear tu web, es como si no existiera para él.
Factores que afectan el rastreo
Google no rastrea todas las páginas de internet por igual. De hecho, cada sitio tiene un presupuesto de rastreo, que es la cantidad de páginas que Googlebot está dispuesto a visitar en un periodo determinado. Si tu web tiene problemas técnicos o una arquitectura deficiente, es muy probable que no se aproveche bien ese presupuesto. Aquí te explico los principales factores que lo afectan:
La estructura de enlaces de tu sitio
La forma en que están conectadas las páginas dentro de tu web es clave. Googlebot navega a través de enlaces, por lo que una buena estructura interna facilita su trabajo.
- Enlaces internos claros y bien organizados ayudan a que Google descubra y rastree todas las páginas importantes.
- Si hay páginas huérfanas (sin enlaces entrantes), es muy probable que nunca sean rastreadas.
- Una arquitectura en forma de silo o jerarquía lógica (inicio > categorías > artículos) mejora el rastreo y también la experiencia del usuario.
- Sitemap.xml mal estructurado o inexistente: Si este no contiene las url’s más importantes de tu sitio web, dificultará su rastreo.
Desde tu página de inicio o menú principal, enlaza las secciones clave. Y dentro de cada artículo, añade enlaces contextuales a otros contenidos relacionados.
La velocidad de carga
Google quiere rastrear de forma rápida y eficiente. Si tu web es lenta, no solo afecta al usuario, también ralentiza el rastreo.
- Cuando una página tarda mucho en cargar, el bot se impacienta (literalmente) y puede dejar de rastrear antes de tiempo.
- Si el servidor responde lento o falla con frecuencia, también limita la capacidad de Google para explorar nuevas páginas.
Usa herramientas como Google PageSpeed Insights o Lighthouse para detectar cuellos de botella en la velocidad. Optimiza imágenes, reduce scripts innecesarios y usa un buen hosting.
Si hay bloqueos en archivos o etiquetas
Hay veces en que, sin querer, le cerramos la puerta a Google. Esto suele pasar por una mala configuración del archivo robots.txt o el uso de metaetiquetas que restringen el rastreo.
- Si bloqueas una carpeta entera en el
robots.txt, todo lo que contenga puede quedar fuera del radar de Google. - Etiquetas HTML como noindex y nofollow
<meta name="robots" content="noindex, nofollow">pueden evitar tanto la indexación como el rastreo de una página. - También hay scripts o tecnologías (como JS mal implementado) que pueden dificultar que Google lea bien el contenido.
- Códigos de respuesta erróneos, que lastran o evitan el rastreo (redirecciones 3xx, errores 4xxx).
Consejo: Revisa regularmente tu robots.txt y las etiquetas <meta> para asegurarte de que no estás bloqueando lo que sí quieres que se rastree. En Search Console puedes ver exactamente qué páginas están excluidas del rastreo.
La frecuencia de actualización de contenido
Google prioriza el rastreo en sitios que demuestran estar vivos y activos. Si una web se actualiza con frecuencia, el bot tiende a visitarla más seguido.
- Un blog que publica contenido nuevo cada semana o que actualiza artículos antiguos puede recibir más atención del rastreador.
- En cambio, si tu web está estática durante meses, Google puede decidir pasar menos seguido.
Consejo: Aunque no puedas publicar todo el tiempo, intenta actualizar artículos existentes, mejorar títulos o añadir nuevas secciones. Estos cambios pequeños pueden incentivar el rastreo sin necesidad de crear contenido desde cero.
Si cuidas estos aspectos, estarás facilitando enormemente el trabajo de Googlebot, lo que se traduce en mejor cobertura de tus páginas, menos errores y más oportunidades de aparecer en los resultados de búsqueda.
¿Qué es la indexación SEO y por qué es clave?
Una vez que Google ha rastreado tu contenido, decide si lo guarda o no en su base de datos. Eso es la indexación. Si tu página no está indexada, simplemente no aparecerá en los resultados de búsqueda, aunque sea el mejor contenido del mundo.
¿Cómo decide Google qué páginas indexar?
Google busca contenido relevante, útil y accesible. Si encuentra una página con poco contenido, duplicada o que carga muy lento, es probable que no la indexe. También influye la autoridad del sitio, la experiencia de usuario, entre otros factores.
¿Cómo saber si tu página está indexada?
Para ver si una página esta indexada, puedes comprobarlo fácilmente escribiendo en Google:site:tuweb.com/pagina-ejemplo
Si aparece, está indexada.
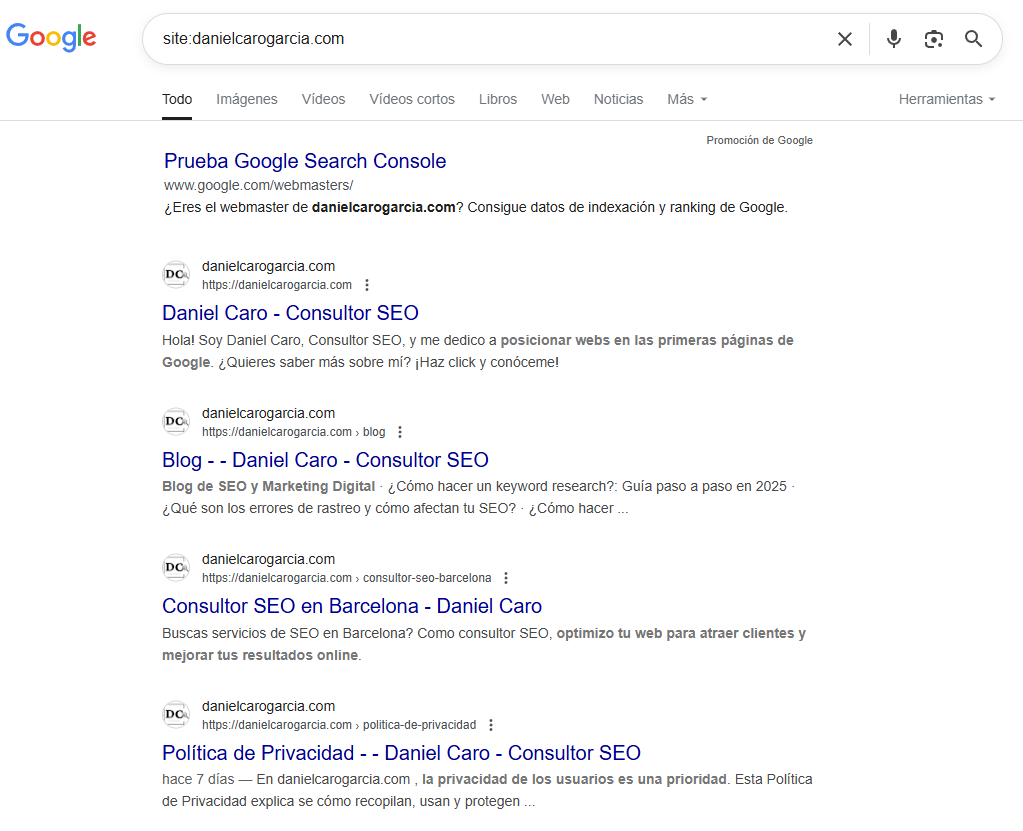
También puedes revisar Google Search Console para ver el estado de indexación de tus páginas, en el informe de cobertura:
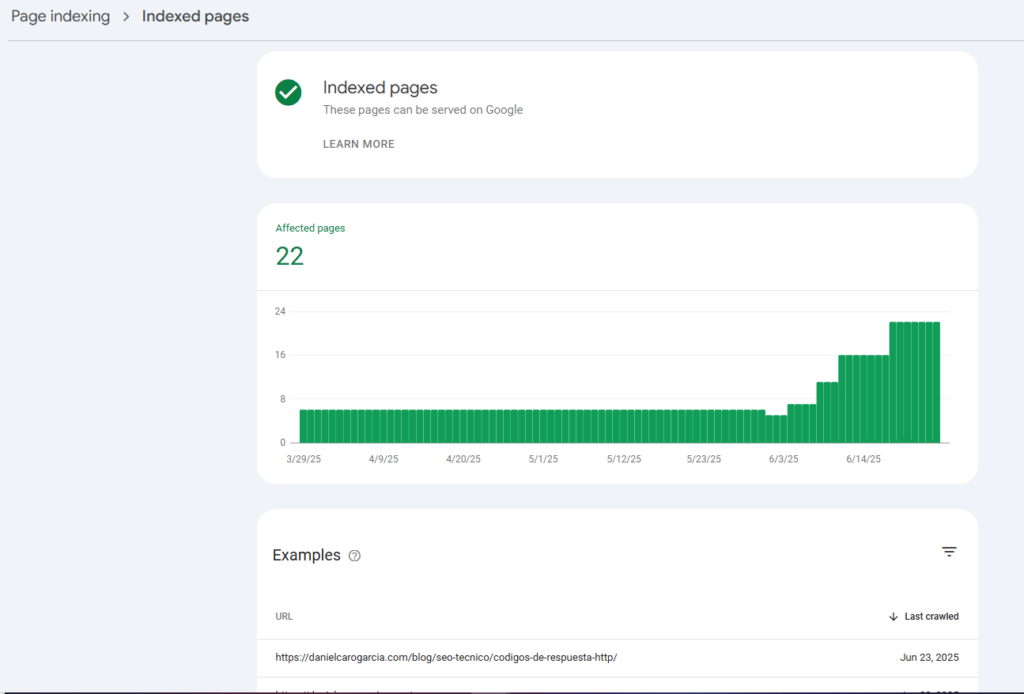
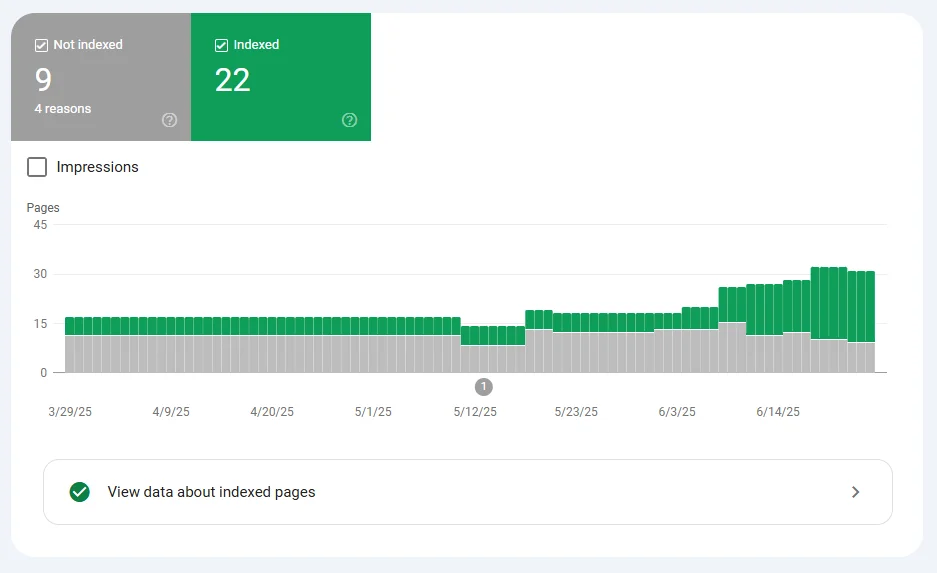
Factores que afectan a la indexación
Aunque una página sea rastreada por Google, eso no garantiza que sea indexada. De hecho, es muy común que el bot visite una página, pero decida no incluirla en su índice, lo que significa que no aparecerá en los resultados de búsqueda.
A continuación, te explico los factores más comunes que pueden impedir o dificultar la indexación de tus contenidos:
Contenido duplicado o de bajo valor
Google evita indexar páginas que aportan información muy similar o idéntica a otras ya existentes.
- Si tu web tiene muchas páginas con textos casi iguales (por ejemplo, fichas de productos sin diferencia o textos generados automáticamente), es probable que no las indexe.
- También puede considerar como «bajo valor» páginas con poco contenido útil, mal redactado o que no resuelven ninguna intención de búsqueda.
Consejo: Aporta valor único en cada página. Usa contenido original, bien estructurado, que responda a preguntas reales de tus usuarios.
Etiquetas «noindex» o canonical mal aplicadas
Una de las razones más frecuentes por las que Google no indexa una página es porque tú mismo (sin querer) se lo estás pidiendo.
- La etiqueta
<meta name="robots" content="noindex">le dice a Google que no debe indexar esa página. - Si usas la etiqueta canonical apuntando a otra URL, Google puede asumir que esa página no debe estar en su índice, aunque no tenga una etiqueta “noindex”.
Consejo: Revisa bien las etiquetas que usas en cada página. Asegúrate de no estar aplicando “noindex” o “canonical” de forma automática sin control.
Falta de enlaces internos o externos
Si una página no está enlazada desde ninguna parte (ni desde tu web, ni desde otras webs), es muy difícil que Google le dé importancia, aunque la haya rastreado.
- Google evalúa la relevancia y autoridad de una página en función de cuántos enlaces apuntan a ella.
- Las páginas aisladas, sin enlaces entrantes, suelen ser ignoradas en la indexación.
Consejo: Crea una estrategia de enlazado interno para conectar tus contenidos entre sí. Si puedes conseguir algún enlace externo (aunque sea desde redes o foros), mucho mejor.
Errores técnicos o velocidad de carga deficiente
Si la página tiene errores técnicos (por ejemplo, tarda demasiado en cargar, devuelve códigos erróneos, usa recursos que no se cargan bien…), Google puede simplemente abandonar el intento de indexarla.
- Un tiempo de carga excesivo hace que el bot se canse antes de terminar de analizarla.
- También pueden influir errores como redirecciones mal hechas o JavaScript que bloquea el contenido.
Consejo: Mantén tu web técnica y funcionalmente optimizada. No solo para el usuario, también para Googlebot.
Falta de intención de búsqueda o utilidad clara
Aunque una página esté bien hecha, si Google considera que no responde a ninguna búsqueda relevante, es probable que no la indexe. El índice de Google no es infinito: solo guarda lo que considera útil.
Antes de crear contenido, pregúntate: ¿esto responde a una duda real de alguien? ¿Qué aporta esta página que no aporte otra ya existente?
Indexar no es cuestión de suerte. Si tus páginas no aparecen en Google, revisa estos factores. A veces, haciendo pequeños cambios puedes lograr que una página empiece a ganar visibilidad en cuestión de días.
Diferencias entre rastreo e indexación
Aunque van de la mano, el rastreo y la indexación son dos fases distintas en el camino que recorre Google antes de decidir si una página aparece (o no) en los resultados de búsqueda.
Una de las diferencias más importantes es que una página puede ser rastreada pero no indexada. Esto significa que Google la ha encontrado y visitado, pero ha decidido no incluirla en su índice. Y por tanto, no podrá posicionarse ni recibir tráfico orgánico.
¿Qué puede hacer que una página sea rastreada pero no indexada?
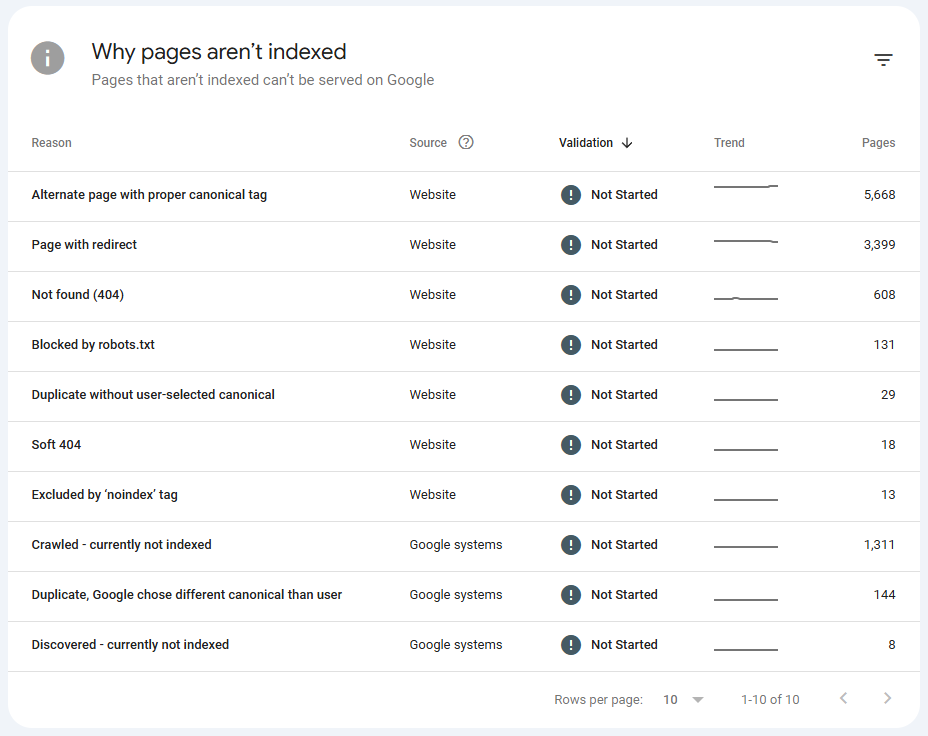
Hay varios motivos por los que Google puede decidir no indexar una página, incluso después de rastrearla. Algunos de los más habituales son:
- Contenido duplicado: Si detecta que el contenido ya existe en otra URL (tuya o de otro sitio), priorizará esa otra y puede ignorar la tuya.
- Falta de valor: Si el contenido no aporta nada nuevo o útil, Google puede considerarlo prescindible.
- Restricciones técnicas: Como etiquetas
noindex, uso incorrecto del canonical, errores de carga o archivos bloqueados enrobots.txt. - Poca autoridad: Páginas que no reciben enlaces internos ni externos, y que están “aisladas” dentro del sitio.
- Problemas de rastreabilidad: Como JavaScript que oculta contenido importante o tiempos de carga demasiado largos.
¿Y al revés? ¿Una página puede ser indexada sin ser rastreada?
Sí. A pesar de que l rastreo siempre ocurre antes, Google puede conocer la existencia de una URL (por ejemplo, por un enlace externo importante o un sitemap). Al descubrirla, según el camino por el que lo haya hecho, puede valorar que esa url sea importante o relevante, e indexarla, incluyéndola en su índice de búsqueda.
Otra casuística por la que Google puede indexar páginas sin poder rastrearlas, es debido a un error muy común en SEO, el cuál es bloquear el rastreo a una página indexada para desindexarla, pensando que al Google no poder rastrearla, no la va a incluir en su índice de búsqueda. Realmente, al no poder acceder a ella, google no podrá ver su contenido, por lo interpretará su estado anterior y seguirá indexada. Para desindexar una página, en este caso, se debería utilizar una etiqueta noindex (entre muchas de las opciones que hay).
¿Por qué es importante entender esta diferencia?
Porque a la hora de mejorar tu SEO, necesitas saber dónde está el problema. Si una página no aparece en los resultados:
- ¿No está siendo rastreada? → Debes revisar la estructura interna, bloqueos técnicos o tu archivo robots.txt.
- ¿Está siendo rastreada pero no indexada? → Entonces hay que revisar la calidad del contenido, la intención de búsqueda, posibles duplicidades, etiquetas mal configuradas, etc.
Entender esta diferencia te permite actuar con precisión y no perder tiempo haciendo cambios que no resuelven el verdadero problema.
Si usas Google Search Console, puedes ir al informe de “Páginas” para ver exactamente qué URLs han sido rastreadas pero no indexadas y conocer el motivo. Es una herramienta clave para mejorar la salud SEO de tu web.
Resumen visual: Factores que afectan al rastreo e indexación
| Factores que afectan al Rastreo | Factores que afectan a la Indexación |
|---|---|
| 🔗 Estructura interna de enlaces | 📄 Contenido duplicado o poco valioso |
| ⚡ Velocidad de carga del sitio | 🔙 Etiquetas “noindex” o canonical mal aplicadas |
| 🚫 Bloqueos en robots.txt o etiquetas | ⛓️ Páginas sin enlaces internos o externos |
| 🔁 Frecuencia de actualización de contenido | 📉 Errores técnicos (códigos, JS, carga lenta) |
| 📍 Sitemap mal generado o inexistente | ⚠️ Falta de utilidad o intención de búsqueda clara |
Cómo optimizar el rastreo e indexación en tu web
La buena noticia es que sí puedes tomar el control. Aunque el rastreo y la indexación dependen en última instancia de Google, hay muchas acciones que puedes llevar a cabo para facilitarle el trabajo y aumentar las posibilidades de que tu contenido aparezca en los resultados de búsqueda.
A continuación, te dejo las claves más efectivas (y accesibles) para mejorar estos procesos.
Revisión del archivo robots.txt
El robots.txt es un archivo que le dice a los bots qué partes de tu sitio pueden o no pueden rastrear. Es una herramienta muy útil… pero también muy delicada. Si bloqueas rutas importantes por error, podrías estar dejando a Google fuera de tus páginas clave.
- Asegúrate de que no estás bloqueando carpetas como
/blog/,/productos/o/servicios/. - Evita reglas demasiado generales como
Disallow: /(bloquea todo). - Comprueba que el sitemap está bien referenciado al final del archivo.
Uso correcto de sitemaps XML
Un sitemap XML es como entregarle a Google un plano detallado de tu sitio: le indica qué páginas existen, cuáles son prioritarias y cuándo se han actualizado por última vez. No tener uno, o tenerlo mal configurado, es como pedirle a alguien que te encuentre en una ciudad sin mapa.
- Incluye solo las URLs que realmente quieras que se indexen.
- Asegúrate de que el sitemap no contenga errores ni páginas bloqueadas por
noindexorobots.txt. - Actualízalo automáticamente cuando publiques o elimines contenido.
- Súbelo a Search Console (sección “Sitemaps”) para que Google lo tenga siempre en cuenta.
Mejores prácticas de enlazado interno
Googlebot navega por tu web siguiendo los enlaces, igual que lo haría un usuario. Si una página no está enlazada desde ningún lugar, será mucho más difícil que Google la rastree e indexe.
- Usa menús y categorías claras que faciliten el acceso a las secciones clave.
- Añade enlaces contextuales dentro del contenido hacia artículos relacionados.
- Evita páginas “huérfanas” (sin enlaces internos) o con demasiados clics de profundidad.
- Prioriza las páginas más importantes enlazándolas más a menudo desde diferentes partes de tu web.
Revisa qué páginas están recibiendo más tráfico o autoridad externa y úsalas como base para distribuir enlaces internos estratégicos.
Mejora de la velocidad de carga y la arquitectura web
Una web lenta o con una estructura caótica ralentiza el rastreo y complica la indexación. Recuerda que Google tiene un presupuesto limitado para rastrear cada sitio. Si tu web tarda mucho o está mal organizada, es probable que algunas páginas queden fuera del radar.
- Optimiza imágenes: comprímelas sin perder calidad y usa formatos modernos como WebP.
- Reduce scripts innecesarios y carga solo lo que realmente uses.
- Activa el almacenamiento en caché para acelerar la experiencia.
- Utiliza un hosting fiable y rápido.
- Organiza tu web con jerarquía clara: categorías, subcategorías, etiquetas, etc.
Herramientas útiles para analizar el rastreo e indexación
No hace falta adivinar qué está haciendo Google con tu web. Hoy en día existen herramientas muy completas (y muchas de ellas gratuitas) que te permiten ver con claridad cómo se está rastreando e indexando tu sitio, detectar errores y tomar decisiones basadas en datos reales.
Aquí te dejo las más útiles:
Google Search Console (gratuita)
Es la herramienta oficial de Google y, si solo puedes usar una al empezar, debería ser esta. Te da información directa del propio buscador sobre el estado de tu sitio.
- Ver qué páginas están indexadas y cuáles no, y por qué.
- Detectar errores de rastreo (como páginas bloqueadas, redirecciones fallidas o excluidas).
- Consultar el archivo
robots.txty los sitemaps enviados. - Enviar manualmente URLs para su indexación.
- Ver el tráfico orgánico que llega desde Google y con qué consultas.
Revisa el informe de “Cobertura” y el de “Inspección de URLs” cada vez que hagas cambios técnicos o publiques nuevo contenido.
Screaming Frog SEO Spider (versión gratuita y de pago)
Es una herramienta de escritorio (disponible para Windows, Mac y Linux) que simula el rastreo de un bot como Googlebot. Ideal para hacer auditorías rápidas y profundas de tu sitio web, cuando tiene un tamaño considerable.
- Detecta errores 404, redirecciones, enlaces rotos o duplicados.
- Analiza las etiquetas
title,meta description,robots, canonicals, etc. - Te dice si hay páginas bloqueadas o sin enlaces internos.
- Exporta informes muy completos en Excel o CSV.
La versión gratuita permite rastrear hasta 500 URLs, suficiente para muchos sitios pequeños o medianos.
Otras herramientas SEO (gratuitas y de pago)
Hay muchas más herramientas que pueden ayudarte, cada una con su enfoque particular. Aquí algunas destacadas:
- Ahrefs: Tiene una sección llamada “Site Audit” que revisa rastreo, enlaces internos, contenido duplicado y más. Muy útil para analizar sitios grandes.
- SEMrush: Ofrece auditorías técnicas, monitoreo de indexación, informes de errores y sugerencias de mejora.
- Sitebulb: Es parecida a Screaming Frog pero con una interfaz más visual y explicaciones detalladas para principiantes.
- JetOctopus: Muy potente en sitios grandes. Te da datos cruzados sobre logs de rastreo reales y estructura interna.
- IndexCheckr (gratuita): Útil para comprobar si páginas específicas están realmente indexadas en Google.
- Google Analytics: Aunque no es una herramienta de rastreo como tal, puedes detectar si ciertas páginas reciben tráfico orgánico o no, lo cual te da pistas sobre su visibilidad.
Saber si tu web está siendo rastreada e indexada correctamente no es una cuestión de suerte ni de intuición. Con las herramientas adecuadas, puedes detectar problemas, optimizar procesos y asegurarte de que tu contenido llega donde tiene que llegar: a los resultados de búsqueda.
¿Quieres incluir una tabla comparativa o un resumen descargable de estas herramientas con sus pros y contras? Puedo ayudarte a prepararla si lo deseas.
Tabla comparativa: Herramientas para analizar rastreo e indexación
| Herramienta | Tipo | Pros principales | Limitaciones | Precio aproximado |
|---|---|---|---|---|
| Google Search Console | Gratuita, web | Datos oficiales de Google, informes detallados | Limitada a sitios propios | Gratis |
| Screaming Frog SEO Spider | Escritorio | Análisis técnico profundo, detecta errores, exporta informes | Gratis hasta 500 URLs, interfaz algo técnica | Gratis / Desde 200 USD anuales |
| Ahrefs | Web, SaaS | Auditorías SEO completas, análisis enlaces, rastreo | Costoso para usuarios pequeños | Desde 99 USD/mes |
| SEMrush | Web, SaaS | Auditorías, seguimiento, herramientas de marketing | Precio elevado para planes completos | Desde 119 USD/mes |
| Sitebulb | Escritorio | Interfaz visual, explicaciones fáciles | Licencia de pago, curva de aprendizaje | Desde 13 USD/mes |
| JetOctopus | Web, SaaS | Gran escala, análisis de logs y rastreo combinados | Más orientado a grandes sitios | Desde 50 USD/mes |
| IndexCheckr | Web, gratuita | Fácil y rápida para comprobar indexación | Funcionalidad limitada | Gratis |
Conclusión
Rastreo e indexación no son solo conceptos técnicos son la base de tu visibilidad en buscadores. Da igual cuánto esfuerzo pongas en tus contenidos si Google no puede encontrarlos o no los considera aptos para indexar no llegarás a tu audiencia
La buena noticia es que puedes tomar el control: Revisar cómo está estructurada tu web, facilitarle el trabajo a los bots, evitar errores técnicos y utilizar las herramientas adecuadas para detectar errores y solucionarlos marcan la diferencia. No se trata de trucos mágicos sino de entender cómo funciona el buscador y adaptar tu sitio a esas reglas
Cada mejora que hagas en estos procesos es un paso más hacia mejores posiciones más clics y más resultados
Y ahora que lo sabes es momento de aplicarlo en tu web
¿Cómo mejorar tu posicionamiento a largo plazo?
Lograr que tu sitio se rastree e indexe correctamente es solo el primer paso para mejorar tu posicionamiento a largo plazo. Debes crear contenido útil que responda a la intención de búsqueda, cuidar la experiencia de usuario, trabajar la autoridad de tu web y asegurarte de que cada página aporte valor real. No se trata de indexar por indexar, sino de construir un sitio donde menos sea más y donde la calidad marque la diferencia. Por supuesto, necesitas una estrategia SEO para desarrollar todo esto en conjunto.
¿Te ha quedado más claro qué es el rastreo e indexación en SEO? Saber cómo funcionan estos procesos es básico para tener una web visible y competitiva en Google. Si tienes dudas, puedes contactar y preguntar sin compromiso.
¿Quieres aprender como hacer crecer tu negocio con SEO y Marketing digital?
Soy Daniel Caro García, consultor SEO con experiencia en ayudar a empresas de mediana y gran envergadura a mejorar su visibilidad online, trabajando tanto en agencia como en cliente final.
Me apasiona el SEO técnico y el análisis del comportamiento del usuario, lo que me permite desarrollar soluciones que no solo mejoran el posicionamiento, sino que también aportan valor real a las marcas con las que trabajo. A través de mi blog, comparto conocimientos, tendencias y estrategias prácticas que facilitan a otros profesionales y empresas mantenerse al día en un entorno digital en constante evolución.
Mi objetivo es ofrecer resultados medibles basados en datos y siempre dentro de las mejores prácticas de SEO, creando una presencia online sólida, ética y de confianza para mis clientes.